Knowledge Base
This page documents the technical structure, published artefacts, and access points of the Varela Digital knowledge base. It describes how editorial data are transformed into reusable semantic representations and how these outputs support navigation and visualisation across the website.
The Varela Digital knowledge base is a published set of static, versioned artefacts derived from the project’s editorial pipeline. It is built from: (i) TEI/XML documents (authoritative textual layer); (ii) a metadata table (CSV) used for indexing and filtering; and (iii) TEI/XML standoff layers that maintain authority records (persons, places, organisations, events) and explicit relation assertions.
The semantic layer is produced from these controlled inputs and released as RDF/Turtle and JSON-LD. The website consumes pre-generated datasets derived from the same sources, allowing interactive exploration (viewer, indexes, map, and networks) without requiring server-side infrastructure.
Design constraints of the knowledge base include: traceability to the encoded text, explicit modelling assumptions, stable identifiers, and reproducible publication through Git versioning. The knowledge base is intended to be reusable independently of the web interface.
Published artefacts
The knowledge base is distributed through a small number of inspectable files. These artefacts provide both (a) the vocabulary commitments (ontology and reused vocabularies) and (b) the instance-level graph describing documents, entities, and relations.
-
Knowledge Base dump:
data_models/kbvd.ttl(Turtle). Aggregated RDF graph containing entities (documents, persons, places, organisations, events) and relation assertions derived from standoff annotations. -
VD ontology:
data_models/ontology_vd.owl(OWL/RDF). Project ontology and namespace declaration for core classes/properties used in the KB. -
Metadata table:
letters_data/metadata/metadata_all.csv(CSV). Normalised document-level metadata used for browsing, indexing, and reproducible dataset generation. - External vocabulary: HRAO (domain-specific relations vocabulary reused as an external dependency for modelling historically meaningful relations).
For implementation details (scripts, transformations, and derived datasets), consult the repository structure and documentation in the project README.
Namespaces and URIs
The knowledge base adopts stable HTTP URIs for all project resources. URIs are designed to be readable, persistent, and compatible with publication on GitHub Pages. The main project namespace identifies instance resources (documents and entities), while the ontology namespace provides the vocabulary layer.
-
Project base namespace (instances):
https://carlamenegat.github.io/VarelaDigital/ -
Project ontology namespace (classes/properties):
https://carlamenegat.github.io/VarelaDigital/ontology/
Within the project namespace, entities are identified through project-controlled identifiers used consistently across TEI, standoff files, and RDF exports. External identifiers (e.g., VIAF, Wikidata, GeoNames) are linked at instance level when available.
Data pipeline
Knowledge base generation follows a deterministic pipeline. TEI/XML provides the authoritative textual representation and inline anchoring, while standoff files provide the curated authority layer and relation assertions. Metadata tables support normalisation and indexing. The semantic layer is generated from these sources and exported as RDF/Turtle and JSON-LD.
- Inputs: TEI/XML documents, TEI standoff (persons/places/orgs/events/relations), metadata CSV
- Transformations: programmatic extraction and mapping to RDF (project scripts and mappings)
-
Outputs: aggregated RDF graph (
kbvd.ttl) and ontology file (ontology_vd.owl)
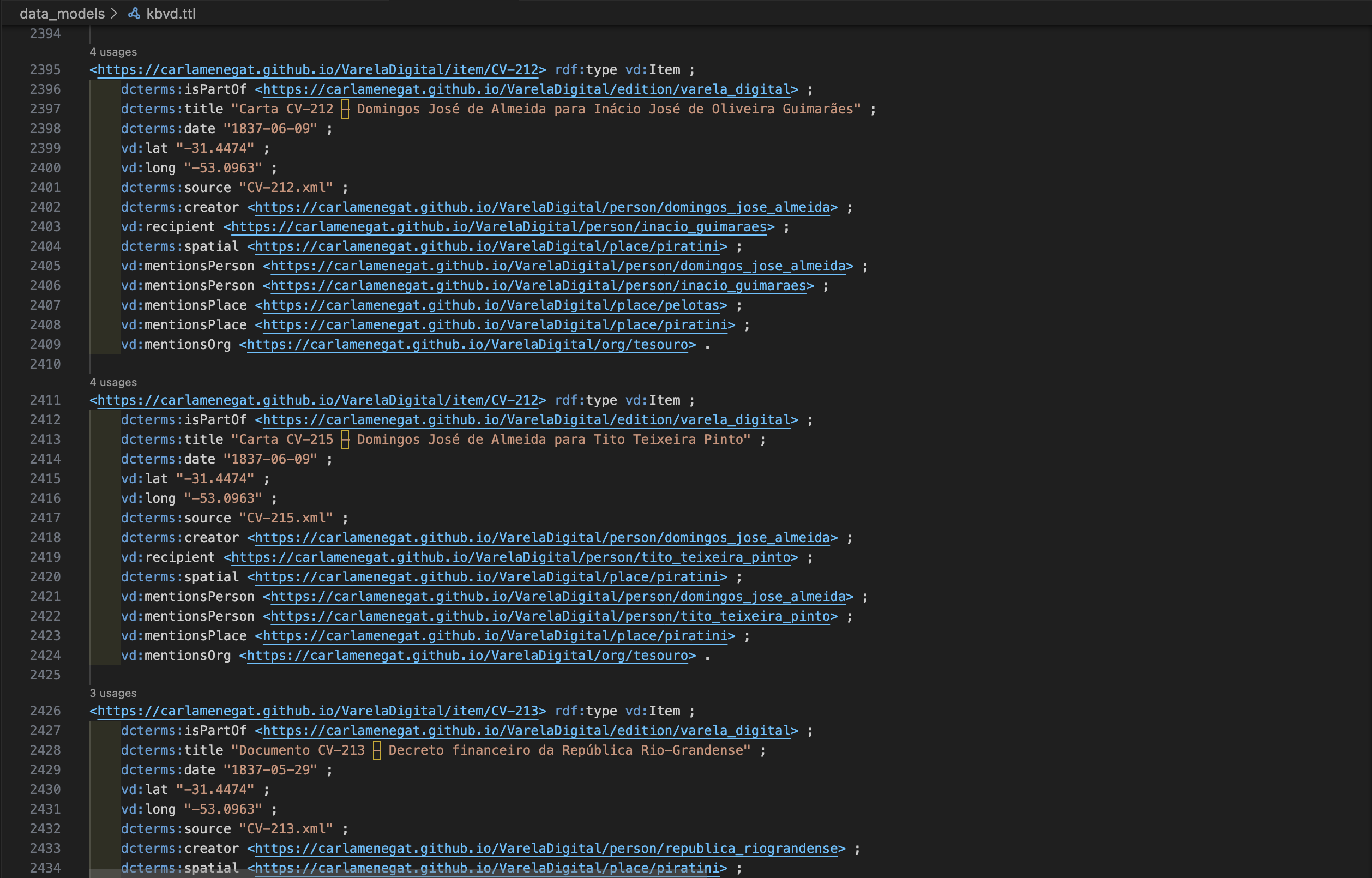
kbvd.ttl) — excerpt of the Turtle serialisation.
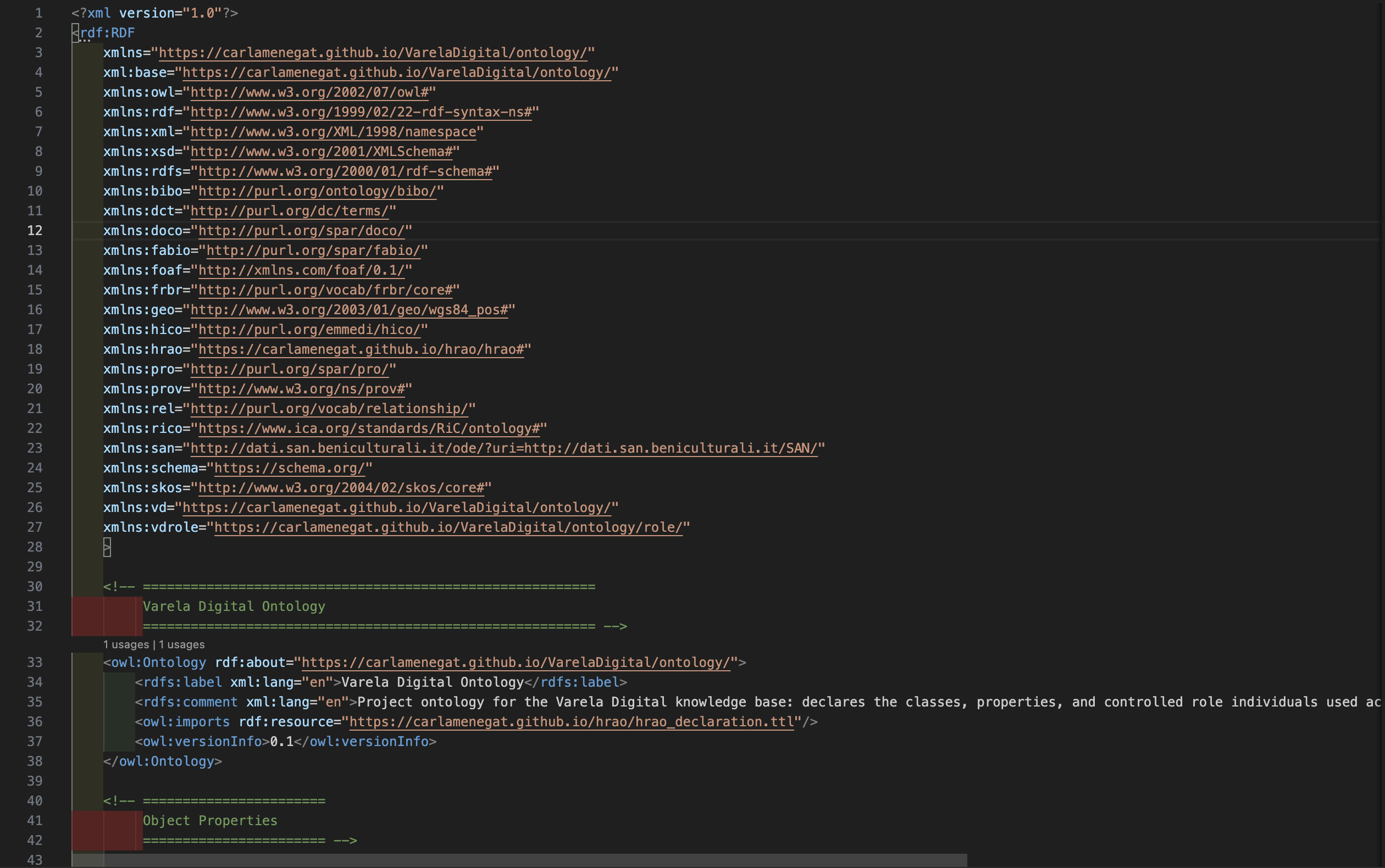
ontology_vd.owl) — excerpt of the OWL/RDF serialisation.
The pipeline prioritises referential integrity: identifiers used in inline @ref attributes and
standoff authority files are validated for consistency before export, ensuring stable links across the
textual edition, the knowledge base, and the visualisation datasets.
Use in visualisations
The map and network views consume pre-generated JSON datasets derived from the semantic layer. This design avoids runtime querying and ensures fast loading and deterministic behaviour in a static web environment. Each visualisation implements a fixed data contract: nodes and edges are generated from curated entities and relation assertions rather than inferred automatically at display time.
In practice, the knowledge base supports visualisations in two ways: (i) by providing stable entity identifiers (persons, places, organisations) that can be rendered as nodes; and (ii) by providing explicit relation assertions (e.g., correspondence relations, kinship ties, institutional links) that can be rendered as edges and filtered by type.
Spatial visualisation relies on place entities aligned to external gazetteers when possible (e.g., GeoNames). Network visualisations rely on typed relations and controlled identifiers, allowing the same actor to be tracked consistently across documents and analytical views.
Data contract (JSON)
Interactive visualisations consume pre-generated JSON datasets derived from RDF exports. The datasets are treated as versioned artefacts: each file corresponds to a specific extraction and modelling state and is intended to be regenerated from the project sources rather than edited manually.
- Social network:
letters_data/data/network/network.json - People network:
letters_data/data/network/network_people.json - Family network:
letters_data/data/network/network_family.json - Organisations (tree):
letters_data/data/network/network_orgs_tree.json
Graph datasets (networks): JSON files representing a graph must expose, at minimum:
nodes: an array of node objects withid(stable identifier) andlabel(display string). Optional fields may includetype,uri, or domain-specific attributes used for styling and filtering.edges(orlinks): an array of edge objects withsource,target, and a relation key such astypeorpredicate. Optional fields may include weights, provenance, or pointers to documentary evidence.
Hierarchy datasets (trees): organisational trees may use a nested structure (e.g.,
children) rather than edges. The minimum requirement is a root node exposing id
and label, and recursively defined children nodes with the same fields.
Publication and access
The knowledge base is published as static, downloadable exports rather than through a live endpoint. This choice aligns with the project’s deployment model (GitHub Pages) and prioritises reproducibility, inspectability, and long-term accessibility over runtime services.
Reuse scenarios supported by this publication strategy include: loading kbvd.ttl into a local
triple store for querying; re-serialising the data into alternative RDF formats; aligning entities with
external authority services; and regenerating derived datasets for map and network analysis.
A public SPARQL endpoint and a server-side API are intentionally out of scope for the pilot phase, but the published RDF exports are designed to be compatible with external infrastructure should future extensions require it.