Project Documentation
Garibaldi Letters Digital Edition
1. Introduction
The Garibaldi Letters project is a digital edition of selected letters by Giuseppe Garibaldi. It aims to provide an accessible, scholarly, and interoperable corpus of his correspondence, presented through a web interface that integrates image facsimiles, TEI-encoded transcriptions, editorial annotations, and English translations. This documentation outlines the technical and encoding methodologies used in the project, as part of a prototype developed for academic assessment and future scalability.
2. General Structure
Each letter is encoded as a standalone TEI-XML document, structured according to the TEI P5 Guidelines and incorporating metadata, transcription, and (where available) translation. The digital edition supports both original Italian texts and corresponding English translations, organized as separate TEI files with synchronized identifiers and segmentation.
3. TEI Header and Metadata
The <teiHeader> is used comprehensively to include bibliographic and archival metadata, ensuring traceability and long-term interoperability. Key components include:
<fileDesc>with full title, author, and editorial responsibility;<publicationStmt>including UUIDs and licensing information;<sourceDesc>referencing the holding institution and IIIF manifest (<ptr target=\"...\"/>);<msDesc>with manuscript identifiers and physical descriptions;<correspDesc>identifying sender, recipient, date, and places involved;<textClass>and<keywords>to classify thematic content.
Metadata is encoded in English, while the body of the document remains in the original language of the letter, that can be Italian, Portuguese, Spanish, French or English.
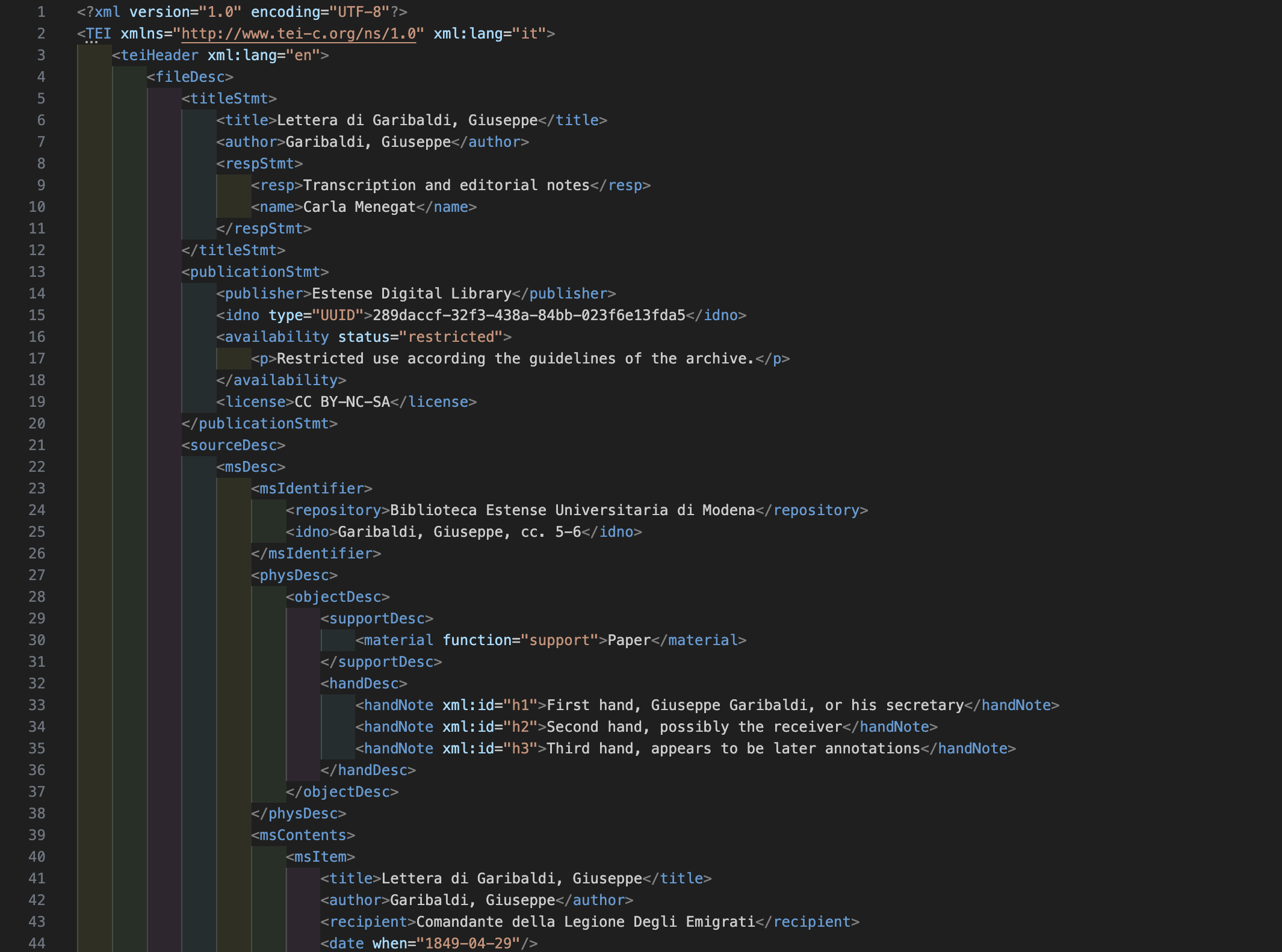
4. Textual Encoding and Epistolary Structure
The structure of each letter is modeled using TEI elements appropriate for epistolary material:
<opener>: includes<dateline>,<address>, and<salute>;<p>: represents individual paragraphs;<closer>: includes<salute>,<signed>, and final<dateline>;<lb/>: used to preserve line breaks;<choice>: used to represent textual corrections or editorial normalization (<sic>and<corr>);<unclear>: for text that is illegible or uncertain;<seg>: for semantically relevant or annotated portions of text.
The <body> is tagged with resp=\"#CM\" to identify the responsible encoder.
5. Facsimiles and IIIF Integration
The edition integrates IIIF (International Image Interoperability Framework) manifests for each letter. Page images are referenced via <facsimile> and <surface> elements, each associated with a canvas ID. The main text <div>s correspond to individual surfaces using @corresp=\"#surface-X\" to allow for precise synchronization between facsimile and transcription.
6. Standoff Annotation and Semantic Layers
Annotations are handled using external standoff XML files. These files are linked in the <encodingDesc> via <refsDecl>, and include:
annotations_comments.xml: interpretive comments on passages or terms;annotations_dates.xml: historically significant dates associated with the correspondence;annotations_physical.xml: seals, stamps, logos, and other material traces in the manuscripts;annotations_places.xml,annotations_persons.xml, etc.: entity references and biographical/geographical data.
Annotations follow the TEI <span> and <event> models, and target specific elements via @from, @ana, and @xml:id.
7. Translation Encoding
English translations are encoded in separate TEI files with the same segmentation logic. These files mirror the structure of the source text and are linked through the interface using surface and file identifiers. The attribute xml:lang=\"en\" is used at the root level to distinguish translated documents.
8. Named Entities and Identifiers
Named entities such as people, places, and organizations are identified using @ref attributes pointing to authoritative URIs when available (e.g., VIAF, GeoNames, LOC). A standoff system of <place>, <person>, and <org> elements includes:
<placeName>and<geo>with WGS84 coordinates;<note>with historical and contextual explanations;<idno>for persistent identifiers.
9. Material Features and Paratext
Physical features of the documents—such as stamps, seals, printed emblems, and addresses—are encoded using a combination of <stamp>, <seal>, and <ab type=\"address\">. Annotations about physical traces are also included in the annotations_physical.xml file.
10. Thematic and Semantic Tagging
Themes and categories relevant to the content of the letters (e.g., nationalism, elections, freemasonry, military organization) are encoded using the @ana attribute on <seg> elements and <term> values within the <textClass> metadata block. These thematic labels facilitate advanced filtering and semantic enrichment.
11. Editorial Principles
- Fidelity to source: Transcriptions are diplomatic but normalized through
<choice>for editorial legibility. - Transparency: All interventions are encoded explicitly with responsibility attribution.
- Extensibility: The TEI structure and modular standoff markup enable future expansion, including annotation crowdsourcing or full-text search indexing.
- Accessibility: The website design ensures usability, clarity, and bilingual access to source and translation.
12. Technologies and Standards
- TEI P5 Guidelines
- IIIF (Presentation API v2.0)
- Bootstrap 5 for frontend UI
- JavaScript for dynamic interface behavior
- JSON-based letter index (
letters_order.json) for navigation and ordering
13. Biographical Dictionary Module
The digital edition integrates a Biographical Dictionary module that consolidates all name entries present in the printed indexes of the Epistolario di Giuseppe Garibaldi, volumes 1 through 14. These entries were automatically extracted, and they were normalized and partially cleaned, both automatically and manually from the PDFs of the original publications, resulting in a set of structured plain-text files, one for each volume. The impossibility of carrying out the entire process automatically was due to the age of the earliest editions, some of which were produced on old presses, making the OCR (Optical Character Recognition) process less accurate.
A Python script processes the extracted data into a single .json file that serves as the data source for a searchable and paginated web interface. The application dynamically aggregates repeated names across volumes, merges their descriptions, and organizes page references by volume. Unique identifiers for each person are automatically generated using a combination of name components and numerical suffixes to resolve homonyms.
The frontend provides a browsable list of all individuals, with support for searching by name or volume. Clicking on a name opens a dedicated entry page displaying associated biographical descriptions and all occurrences in the correspondence volumes.
To enhance accessibility, a translation feature has been integrated into each entry page using the DeepL API. When activated, this feature sends the original Italian descriptions to a local Flask backend, which securely relays the request to DeepL's translation service and returns an English version of the text. Both original and translated content are presented side by side for clarity and comparative analysis.
14. Conclusion
This prototype of the Garibaldi Letters digital edition represents an initial effort to approach nineteenth-century correspondence through semantically aware, technically structured encoding. While several layers of annotation and metadata have been implemented, a fully semantic web integration—particularly through the conversion of entities into RDF aligned with relevant ontologies—remains a goal for future development.
The editorial model adopted here is grounded in international standards for digital scholarship and has been structured with attention to long-term sustainability and scholarly reuse. However, it must be emphasized that this edition was developed as part of a learning process, and reflects both the possibilities and limitations of an academic prototype at this stage of study.